工程是个什么东东
无论是使用Keil、CubeMX还是以后可能会涉及的Clion,开始写代码之前总有一步叫做新建工程,那么工程是什么呢?
抛开又大又空的理论不谈,工程(Project)是什么其实很好理解,就是将你想要做的东西进行一个封装,形成一个易于移植的、与外界耦合度较低的独立个体。用实物举一个简单的小例子:
你要做一辆小车,那么“小车”就是工程的名字,而工程中用到的组件可能包括轮子、电机、驱动以及小车的外壳,这些东西之间有很强的耦合性,他们相互作用共同组成了小车这个工程,而这整个工程与外界的耦合度并不高,所以你的小车可以随处乱跑,无论拿到宿舍还是教学楼都可以正常工作。
在硬件中是这样,软件中也是这样。
你新建了一个名为Car的工程,在为其写代码的过程中你可能会用到单片机接口库、电机驱动库等等,他们之间耦合度很高,但是整个工程与你的电脑之间只是一个简单的存储的关系,所以整个工程文件夹可以随意在不同电脑之间迁移并且都可以正常工作。
言外之意:
当你希望别人在他的电脑上运行或者测试你的工程时,请将整个工程文件夹打包发给对方,而不是仅仅将main.c里面的代码复制然后把文本发过去或者仅仅将main.c文件发过去。
CubeMX中某些不起眼的点
Pinout & Configuration
当你想得知自己配置的引脚还有没有相同功能的复用引脚时,可以试试按住Ctrl然后拖动已经设置的引脚,拥有相同复用功能的引脚就会闪烁,只要在其上放开即可。
Clock Configuration
选择完时钟源之后可以直接在某个频率设置中输入频率,按下回车即可由CubeMX为你配置已知的解决方案。
Project Manager

用于设置集成环境工具链,笔者使用Keil故选择MDK-ARM。

用于设置工程代码的最小堆栈大小

- 将所有用到的函数库拷贝到工程文件夹
- 仅拷贝必要的库文件
- 将必要的库文件添加到工具链的工程配置文件作为参考
学习的过程中建议选择第三个,以便使用过程中参考库函数代码。

- 为每个外设生成一对“.c/.h”文件
- 重新生成时备份初始生成的文件
- 重新生成时保留用户代码
- 删除未重新生成的以前生成的文件
建议勾选图中的三个,有助于规范化工程中的文件结构。
MDK工具链下的工程文件夹结构
来看一个典型的工程个文件夹的文件树:
D:\APPLICATION_DATA\CLION_PROJECTS\EXAMPLE
│ .mxproject //CubeMX工程配置文件
│ Example.ioc //CubeMX工程文件(点击打开CubeMX
├─Core //工程核心代码文件夹
│ ├─Inc //工程核心代码-头文件夹
│ │ gpio.h
│ │ main.h
│ │ stm32f4xx_hal_conf.h
│ │ stm32f4xx_it.h
│ └─Src //工程核心代码-源文件夹
│ gpio.c
│ main.c
│ stm32f4xx_hal_msp.c
│ stm32f4xx_it.c
│ system_stm32f4xx.c
└─MDK-ARM //MDK工程文件夹
Example.uvoptx //MDK工程配置文件夹
Example.uvprojx //MDK工程文件(点击打开Keil
startup_stm32f401xc.s //初始化代码CubeMX模板生成的代码结构
可能没什么必要的前置小知识:
C语言中用
/*被注释内容*/来表示段注释; 用
//被注释的内容来表示行注释。
观察CubeMX生成的代码不难发现其中的注释很大一部分都是一样的,这些注释其实是十分科学地分配了用户写代码时的代码结构。
忽略其中一些无用的部分,我们将大体的框架拿出来看一看:
!!首先最先强调的一个问题:
!!用户代码应该写在Begin和End之间,即:
!!/* USER CODE BEGIN xxxx */和/* USER CODE END xxxx */之间,
!!否则将导致的后果是:你的代码会在下一次重新生成时被删除。
/* USER CODE BEGIN Header */
//书写用户头(依照Doxygen的注释形式,在官方信息的基础上添加文件信息)
/* USER CODE END Header */
/* Includes ------------------------------------------------------------------*/
/* Private includes ----------------------------------------------------------*/
/* USER CODE BEGIN Includes */
//书写用户头文件包含
/* USER CODE END Includes */
/* Private typedef -----------------------------------------------------------*/
/* USER CODE BEGIN PTD */
//书写用户变量重命名
/* USER CODE END PTD */
/* Private define ------------------------------------------------------------*/
/* USER CODE BEGIN PD */
//书写用户替换宏定义
/* USER CODE END PD */
/* Private macro -------------------------------------------------------------*/
/* USER CODE BEGIN PM */
//书写用户宏
/* USER CODE END PM */
/* Private variables ---------------------------------------------------------*/
/* USER CODE BEGIN PV */
//书写用户变量定义
/* USER CODE END PV */
/* Private function prototypes -----------------------------------------------*/
/* USER CODE BEGIN PFP */
//书写用户函数声明
/* USER CODE END PFP */
/* Private user code ---------------------------------------------------------*/
/* USER CODE BEGIN 0 */
//书写函数定义等一些不属于以上分类的内容
/* USER CODE END 0 */
/* USER CODE BEGIN 1 */
//书写一些函数比HAL初始化更底层的函数调用
/* USER CODE END 1 */
/* MCU Configuration--------------------------------------------------------*/
/* USER CODE BEGIN Init */
//书写用户MCU初始换代码
/* USER CODE END Init */
/* Configure the system clock */
/* USER CODE BEGIN SysInit */
//书写用户系统初始化代码
/* USER CODE END SysInit */
/* Initialize all configured peripherals */
/* USER CODE BEGIN 2 */
//一般用于书写外设或其他功能初始换代码
/* USER CODE END 2 */
/* USER CODE BEGIN WHILE */
//书写while(系统已经生成)
//书写循环中代码
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
//书写循环中代码
//书写与前方循环对应的括号(系统已生成)
/* USER CODE END 3 */
/* USER CODE BEGIN 4 */
//常用于书写函数定义
/* USER CODE END 4 */
/* USER CODE BEGIN Error_Handler_Debug */
//用户添加自己的错误处理代码
/* USER CODE END Error_Handler_Debug */
/* USER CODE BEGIN 6 */
//用户添加自己的断言处理代码
/* USER CODE END 6 */关于我用CubeMX快速找到芯片资料那些事
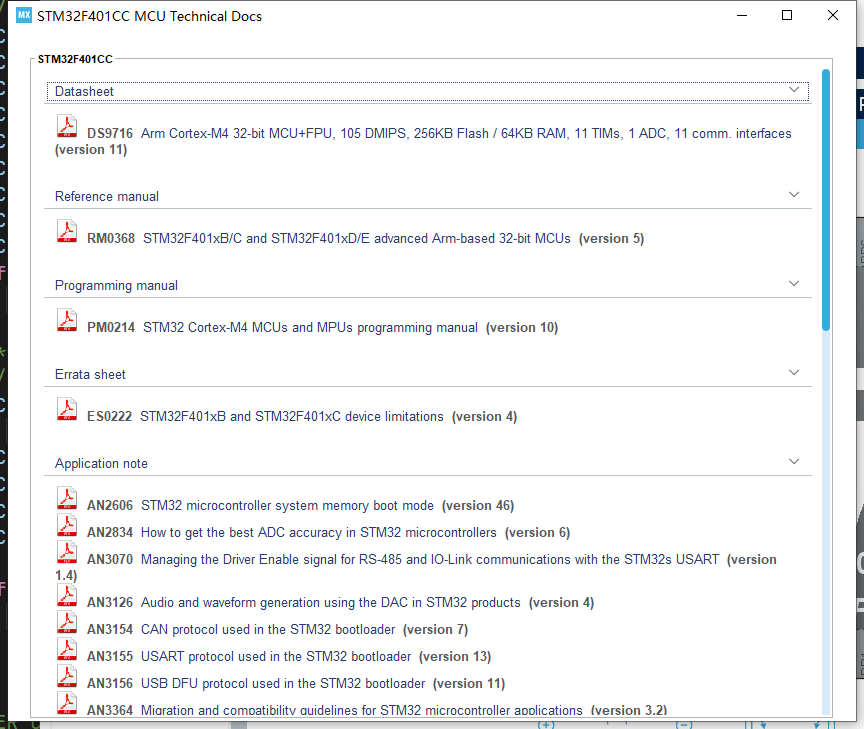
选过芯片之后可以通过CubeMX来快速获得所选的芯片的各种资料:
资料很全,F401的资料如图:
点点点是在干什么
第一次接触CubeMX的大家可能还搞不懂我们点来点去是在干嘛。
简单地说,我们的每一次点击都会对单片机的寄存器进行一次配置,而右面的图片其实就是一个放大了的单片机,上面的每一个引脚都对应着单片机上面的一个引脚。
代码格式
笔者学习语文的时候就经常听到一句话:字体是一个人的脸面
现在笔者在写代码,不得不说,代码的格式甚至也可以上升到程序员脸面的地步。
什么样的代码格式算是好的呢?
有一个很有趣的注释:
//A few days ago, only God and I understood my code.
//Now only God understands it.几天前只有上帝和我能看懂我的代码,现在只有上帝懂了。
好的代码不应该是这样的,而应该是傻子都可以理解作者的意图。
换句话说,代码格式至少应该清晰明了、整洁统一,若能将逻辑结构划分开来则为更好。
直观地来感受一下:
//一个简单的时间片轮询函数实现
void TaskDicision(void) {
for (int i = 0; i < TaskNum(taskList); i++)
{
if (taskList[i] != NULL) {
taskList[i]->taskTimer += ITperiod;
if (taskList[i]->taskTimer >= taskList[i]->taskTimePiece)
{
taskList[i]->taskTimer = 0;
taskList[i]->taskHandler();
}}}
}//一个简单的时间片轮询函数实现
void TaskDicision(void) {
for (int i = 0; i < TaskNum(taskList); i++) {
if (taskList[i] != NULL) {
taskList[i]->taskTimer += ITperiod;
if (taskList[i]->taskTimer >= taskList[i]->taskTimePiece) {
taskList[i]->taskTimer = 0;
taskList[i]->taskHandler();
}
}
}
}应该不用多说什么,可读性高下立判。
当然这其实是一个相对较极端的例子,一般的使用中我们很少会用这么多层的括号互相嵌套。但是即使是少层的内容嵌套也需要一个良好的格式,主要是遵循以下几点其实就可以写出漂亮的代码:
- 在每层花括号内部进行缩进
- 对于
for或者if之类的有明显逻辑结构的语句即使并没有用到花括号也最好进行缩进 - 在不同的代码功能之间最好以换行来进行分隔
代码注释
代码注释一直是一个非常值得探讨的话题。
不仅仅是由于你的代码是否有注释决定了别人能否读懂你的代码,更是由于能否读懂别人的注释决定了你是否能够读懂别人的代码。
提到代码注释就不得不提的东西叫做”Doxygen“,它可以根据代码之中的注释来为工程生成一个详尽的文档,而程序员所需要付出的代价很简单:按照Doxygen的注释标准来编写注释。
就是因为很多开源库都在使用Doxygen(没办法,给的实在是太多了太好用了),以至于Doxygen的注释标准甚至成为了一种几乎公用的良好注释标准。
其实HAL库中的很多注释都是基于Doxygen的注释标准的,因此了解这种注释标准对大家读懂注释有很大帮助。
由于全写完篇幅有点长,所以大家可以自己看看这篇文章。