前言
所谓前言,不过是一些没营养的废话而已,不感兴趣的同学可以直接跳到后面感兴趣的内容来看,当然也可以选择直接退出文档并感叹又被这可恶的老学长浪费了自己人生中宝贵的一分钟(不过大家真的这么选择了老学长会很伤心的T_T

最近几天看到越来越多的小朋友已经开始学习C语言了,作为一个大学生涯已经年过半百的老头,笔者表示十分欣慰,但是也在暗自感慨自己已经被卷的面目全非了。毕竟当年笔者刚开始学习C语言的时候也是十一假期实在没什么事干才开始学的(既然提到十一假期那就不得不提一下笔者当年的十一还是七天假(炫耀)
好了好了,回归正题
大家提出的一些问题的确牵涉到了一些码农们一旦提起就会导致一番腥风血雨的,但是其实又无关紧要的那么一些问题;而另一些问题则是牵涉到了刚开始学习编程一定会遇到的,又没什么人会特地教的问题(通常遇到这类问题的同学会有两种结果:被劝退or忽略它,在余生的编程生涯中慢慢感悟
本着对带自己入门学长的感激(其实就是闲的没啥事干)笔者打算把这些话题单独拿出来浅显的说一说。能力有限,如有谬误,望读者斧正。(开始套盾)
Hello World
就像人人都会有一门母语一样,每个编程者也都会有一门母语。我们学院的绝大部分同学们的母语应该都和笔者一样----C。说实话,随着笔者接触的编程世界(或者说技术世界?)的边界慢慢扩展,笔者越发开始觉得以C作为母语真的是一件很幸运的事,笔者也推荐大家将C作为自己的母语来学习(虽然Python确实比C简单又方便)。
计算机世界的一切都是应运而生,能经过时间考验的C自然也不例外。C把接近底层的几乎一切都暴露在你的面前,但是学完C之后大家有极大的可能会产生一种无力感----C好像也没有大家说的那么高级嘛。隔壁宿舍的小明学完html+css+js之后都可以自己搭网页了;对床的小刚学了java昨天还在和我炫耀他写的安卓程序,而我只能给他看我几十行代码调试了两天的成果----输出100以内的素数。
别担心,笔者曾经也和大家一样,但是C对大家的影响是潜移默化的,当你接触的东西慢慢开始多了起来的时候,你才会慢慢理解原来大佬说的都是有道理的----原来C真的可以生万物。
但是笔者也不是想传达一种“万般皆下品,惟有学C高”的理念,编程语言毕竟只是工具,需要GUI开发的时候笔者也会欣然的拥抱面向对象语言,平时写点实用的小程序的时候笔者也会振臂高呼:人生苦短,我选Python。只是C让你更加容易的理解一些思想和方法出现的原因,让你对其他语言更加包容,能更加从容的面对编码这件事,还有操作系统等软硬件临界区里的一切。
完蛋了,又说了一堆废话...

关于开发环境
开发环境其实是一个很容易引起腥风血雨的问题,就像咸豆腐脑和甜豆腐脑的口味偏好一样
(BTW咸豆腐脑yyds。这种问题往往没有谁对的谁错,只是是否适合以及个人喜好的问题。但是一些不好用的环境(如受尽诟病的VS2010)也确实是不会有人推荐你使用,就像也有些东西大家都不会吃(咳咳,卫生原因考虑这里就不指明了但是也完全不建议对使用这些不好用的环境的初学者报以敌视的攻击态度(如在学校的C语言教学群内大吹特吹某环境进而影响老师教学),他们只是还没有接触到更好用的开发环境或者受某些原因所迫,信息差并不能成为你高傲的漠视他们的资本。
作为开发者,我们应该更多的关注编码这件事本身,而不是锦上添花的环境。
关于开发环境,笔者推荐使用JetBrains家的Clion,不单单是夹带私货,也确实是因为这在大家后续的开发旅途中很可能会是常伴左右的IDE。
当然,其实Clion也并不是开箱即用的,使用Cmake组织工程这件事可能会卡住相当一部分想向工程中添加文件的小朋友,不过了解这方面的内容对你未来的开发旅途其实并不是无用的。
当然,为了让这类问题不再成为问题,笔者在这里简单带过一下大家可能会出问题的地方:
应对英文环境以及新建工程
首先建议的当然是学会适应。
解决方法自然也是有的:大家大可以自己在搜索引擎中搜索Clion 中文插件,很容易的就可以获取到安装中文插件的教程。
实在不会的话笔者在这里贴上一份C语言中文网的安装及汉化教程,建议大家优先自行搜索锻炼自己的信息查找与筛选的能力。
新建工程这类的内容当然也相信大家可以在网络上找到自己需要的答案,不过保险起见这里还是粘一份在这里:使用Clion编写C语言程序
教程中提到了关于中文乱码的问题,这需要一些有关文件编码的知识,笔者在后面会专门提及这个问题。
向工程中添加文件以及修改目录结构
这部分内容其实在绝大部分同学的C语言学习过程中都是不会涉及的,因为大家学习过程中写的代码往往一个文件就够用了。
但是不排除部分同学会有类似的需求;以及就算现在没有,将来也早晚会有的。所以笔者在这里简单提及一下Clion中Cmake相关的内容:
-
Clion工程通过CMakeLists.txt来管理整个工程;
-
新建工程时会自动生成CMakeLists.txt文件,所以C语言工程是开箱即用的;
-
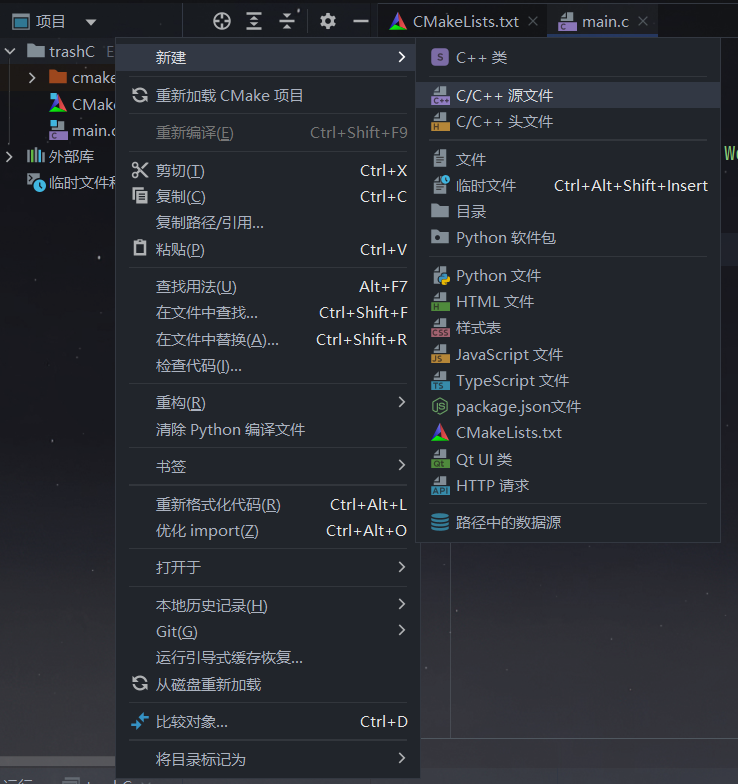
如果你想向工程中添加一个新文件,首选的是使用IDE内提供的方式:

此处如果选择了创建关联头,就会在新文件同级目录下创建同名的头文件(.h);
此处如果选择了添加到目标,就会自动帮你修改CMakeLists.txt,即添加后就可以正常编译运行。
-
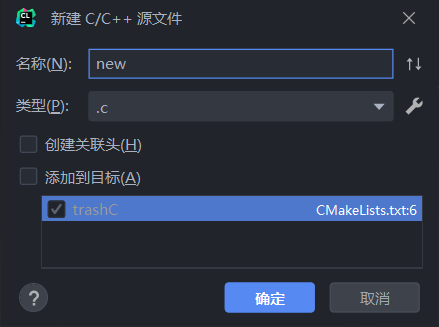
如果你想向工程中添加已经存在的文件,直接将那个文件复制到工程路径即可,但是需要自己修改CMakeLists.txt文件:
把你添加的文件名写到这个指令后面,就像图里做的一样:
-
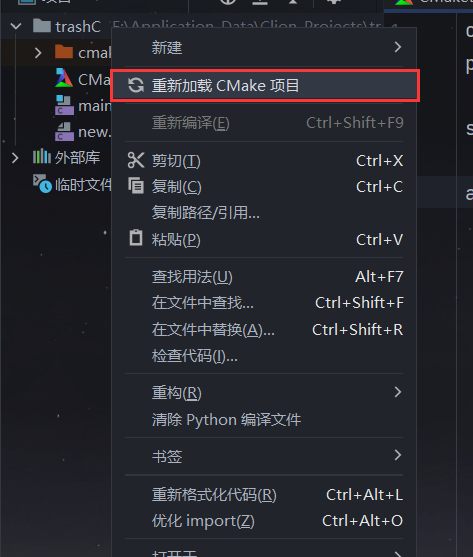
Clion的CMakeLists.txt的每次修改都会导致IDE修改一些工程内的文件来保证你编译成功,但是有的时候你修改过CMakeLists.txt并保存或者私自添加文件到工程目录中后,IDE由于发呆可能没有自动更新文件,这时你可以在跳出来的窗口中点击启用自动重新加载来让IDE自动更新文件:
也可以右键左侧窗口内的任意文件唤起菜单,点击其中的重新加载Cmake项目来手动更新文件:


关于文件编码
相信只要是写过代码的同学都会被控制台输出中文乱码这件事搞得挠头,这主要涉及了文件编码的知识。
解决这个问题最方便的方案就是:使用英文作为输出(doge。
这其实是一个初学很容易发懵的点,让人挠头的主要原因是这个话题有着很大的历史包袱。
在这里就简单的和大家介绍一下相关的内容,不涉及各种编码的编码细节,有感兴趣的同学可以通过搜索引擎以及各个编码标准的官方文件/网页来继续深入了解。
计算机的世界没有魔法
首先大家一定要意识到一件事情,计算机这种硅基生物是人类一手制造出来的。其中的一切内容,无论名称多么高端,实现多么复杂,都一定是有迹可循的。所以在计算机的世界中没有魔法。
一切的开始----ASCII
你有没有想过计算机为什么叫“计算机”?一定是因为它能计算对吧!
但是很不幸,它也只能计算。(当然,抛开目前科技前沿的某些奇怪发现。至少在计算机刚发明出来的时候是这样的。
计算机只能计算,换句话说就是计算机只能和数字相关的事情。但是人类的语言(以英语为例)都是在人类发展过程中产生的,很大程度上和数字关系并不大,那怎么让它们和数字产生关系呢?
相信对C语言已经有了解的同学已经想到了:ASCII码。
ASCII将0-127共128个数字映射到了所有的英文字母以及一些常用的功能键上,如:换行、回车以及退格等。自此,通过ASCII码表的中转,你就可以在计算机内使用数字来表示字母以及一些功能键了。
Unicode一统天下
随着计算机在不同的国家间普及,每个国家都想把自己国家的字符塞进计算机中。但是英语已经最先霸占了0-127位置的字符,所以其他国家就只能在后面继续添加自己的字符。
不过无论怎么加,英文的编码数字肯定都是不变的,这也解释了一个问题:
为什么无论使用什么编码都不会导致英文乱码。
但是大家很容易就会想到一件事:各个国家将自己的字符添加到编码中这件事是同时发生的,所以显然每个国家都有一套自己的编码标准(例如中国自己的GB2312)。这意味着什么呢?在国内或许没什么,但是一旦上升到世界视角,就可能出现128这个数字在每个国家都对应着不同的字符这样的尴尬事情。
于是在这样的背景下,Unicode诞生了。Unicode用一种很夸张,也很简单粗暴地方式解决了这个问题:
编一张巨大的表,把所有的字符都放进去。(可以想见,如果将来大猩猩学会使用电脑了,Unicode可能会拓展出猩猩语的字符
此外也延伸出来一件很重要的事情:Unicode并不是编码方式,而是一张巨大的表,或者说标准点叫字符集,这也是你费尽心思想在IDE中找到Unicode编码但是找不到的原因。
说到这里一些想得多的同学可能又感到奇怪了:
同样是表示数字和字符关系的一张表,凭啥GBK/GB2312就是编码,而Unicode就只是字符集呢?
这里可能涉及到一点点大家没接触过的词汇了,希望大家尽量看看看,了解即可。
用127这个数字举例:它的16进制是0xFF,在存储和传输中显然只占用一个字节。但是在GB2312中有超过127的数字存在,这就意味着GB2312所涉及到的数字的存储和传输需要不只一个字节(实际上需要两个字节)。既然其他的数字都需要两个字节,为了传输和解析信息的简便性,那原本只需要一个字节的127就只好也占用两个字节,从0xFF变成了0x00FF。而这占用多少字节就是编码标准所规定的事情。所以编码标准并不仅仅只是一张表而已。
但是Unicode就不一样了,它真的就只是一张表而已。
GB2312与GBK
从之前的描述不难推断出,GB2312其实并不是全世界通用的编码,它只包含英文与部分中文(貌似还有一些日文的假名,不懂不敢乱说),后续随着汉字的增多,原来的GB2312表装不下了,所以有了更大的表:GBK。它向下兼容GB2312编码(意思就是GB2312编码的文件,GBK也可以解析)。就是这样,其实很简单对吧?
UTF-8传奇
已经讲到这里其实就没什么可以继续深入的内容了,刚刚说过Unicode并不是一种编码标准,而只是一个字符集,那就没有一种支持全世界语言的编码标准吗?
UTF-8这不就来了吗。
UTF-8是一种编码标准。换句话说,UTF-8是Unicode这张表在编码标准上的实现。但是它不是简单的拓展字节数那么简单,因为Unicode收录的字符太多,这种存储方式会导致占用内存过多进而影响到计算机的运行。所以UTF-8规定了一些巧妙的标准来实现减小字符编码所占的内存,具体实现就不在此赘述了。
还有不得不提的一点就是:UTF-8正在并且已经成为当前世界最通用的编码标准。
可以看到的是:目前互联网上与字符编码有关的一切都在拥抱UTF-8编码,所以我们也来一起拥抱UTF-8吧。毕竟让散乱的标准统一并不仅仅是物理学家在做的事情,也是计算机科学家们在做的事情。
空中花园的破碎
前面所讲的这些其实都是知识性的内容,对我们实操并没有什么帮助。而这座空中花园是否破碎的关键就是能否过了实践这一关。毕竟实践是检验真理的唯一标准。
但是很不幸,这座空中花园很快就会被同学们宣告破碎,例如群里小伙伴的这个有力的反例:
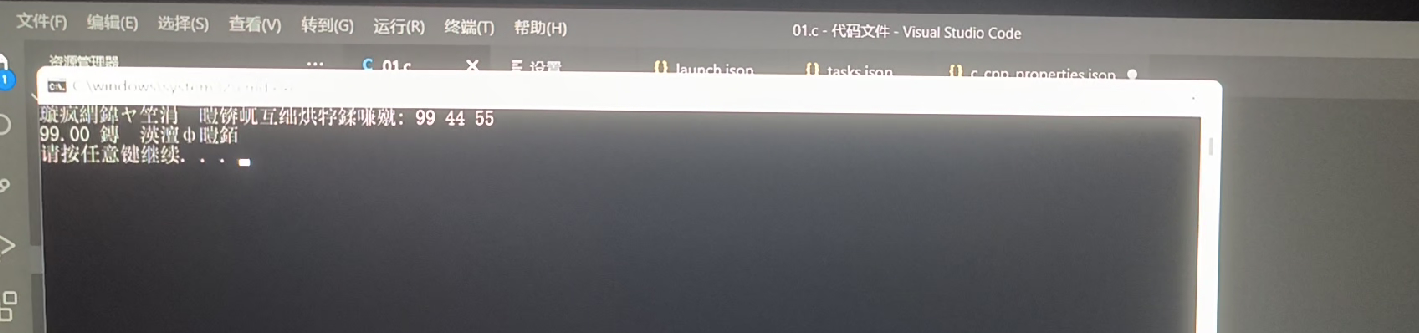
从聊天记录判断这位同学应该是使用UTF-8来对文件进行编码的,所以这个同学就可以立即起立然后给老学长一个大逼兜,大吼道:“乱说!你不是说UTF-8支持世界上所有的字符吗!?我电脑上怎么乱码了!?你这厮招摇撞骗,看洒家打死你!!!”
于是被打的奄奄一息的老学长用尽最后一口气说出了遗言:“下次往群里发电脑上的图片请用QQ快捷键:Ctrl+Alt+A截图,录屏请用:Ctrl+Alt+S,手机录的真心看不清~~”
开个小玩笑,不过大家确实要注意这件事哈~
这个例子到底有没有宣告着空中花园的破碎呢?很不幸并没有。
在这里很可能同学们忽略了一个小细节(这当然是笔者故意如此组织来让读者忽略的):有了编码标准,就一定会有对应的解码标准。
那么现在举个简单的例子:用英语翻译成汉语的翻译器可以把西班牙语翻译成汉语吗?当然不能。
同理,GB2312的解码器自然也不能把UTF-8编码的内容翻译成你想要的内容。
至此我们了解到一件事情,那就是显示出正确字符的充分必要条件有两个:
- 编码标准应该支持你想显示出的字符
- 编码标准和解码标准应该是对应的
那我们回来看上面这个问题:
不知道你有没有想过:为什么代码里面显示的字符明明是正确的,但是到了控制台就不正确了呢?
我们把它拆成两部分来看:
首先是代码显示的之所以是对的,是因为你使用了UTF-8的编码,而IDE使用了UTF-8来进行解码,所以一切都像是暑假放假第一天的那个傍晚一样美好。
接下来我们把目光转向控制台。既然IDE知道你使用了UTF-8编码,那么编译得到的程序输出的字符一定是使用UTF-8编码的。程序要将这串内容想显示在控制台,就必须经过操作系统的系统调用来把这串字符交给操作系统,然后操作系统会负责将这串字符输出到用户的控制台上。
上述可能涉及一点点操作系统的知识,但是读者只需要知道:在程序的输出和控制台显示之间,经过了你的Windows操作系统。很不幸,Windows操作系统默认的解码方式是GBK/GB2312,自然不能输出你想要的字符。
既然搞懂了这件事情就不难想到这个问题有两种解决方式:
- 不改变操作系统的解码方式,转而将程序改变为GB2312编码,从而使编解码一致;
- 不改变程序的编码方式,转而将操作系统改为UTF-8解码,从而使编解码一致;
网上的巨大部分教程都会教读者第一种方法,当然第二种方法也是可以实现的:
打开Windows的语言设置,找到下面这个选项:
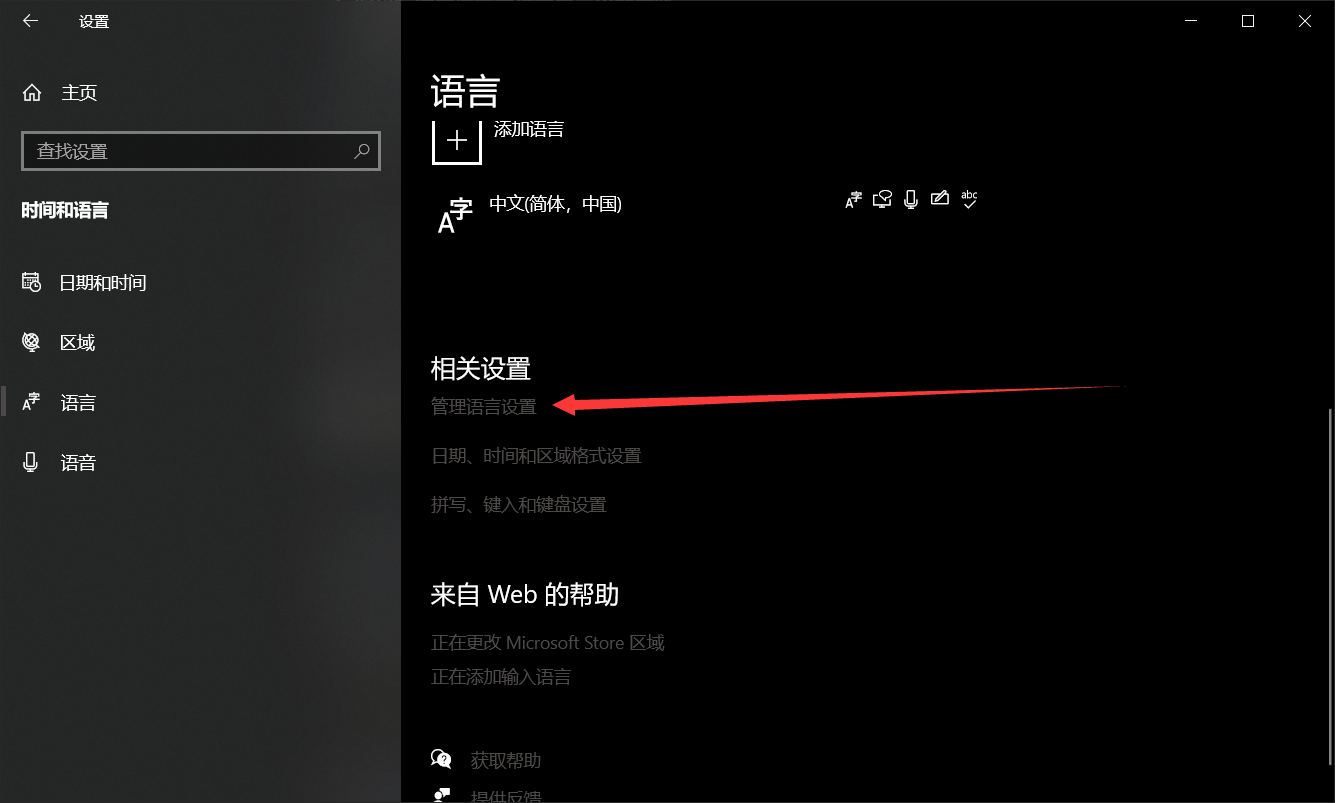

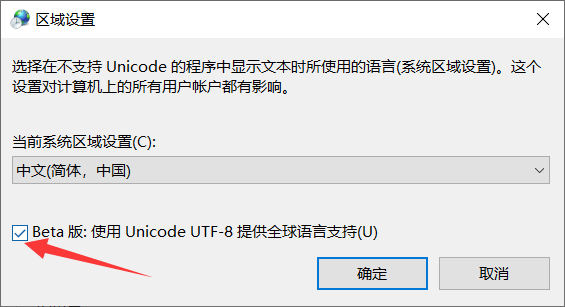
勾选后重启即可。
注:笔者操作系统环境如下
版本 Windows 10 专业版
版本号 21H2
安装日期 2022/4/15
操作系统内部版本 19044.1889
体验 Windows Feature Experience Pack 120.2212.4180.0
显然,经过此项设置的笔者的电脑已经可以在UTF-8编码下正常显示了:
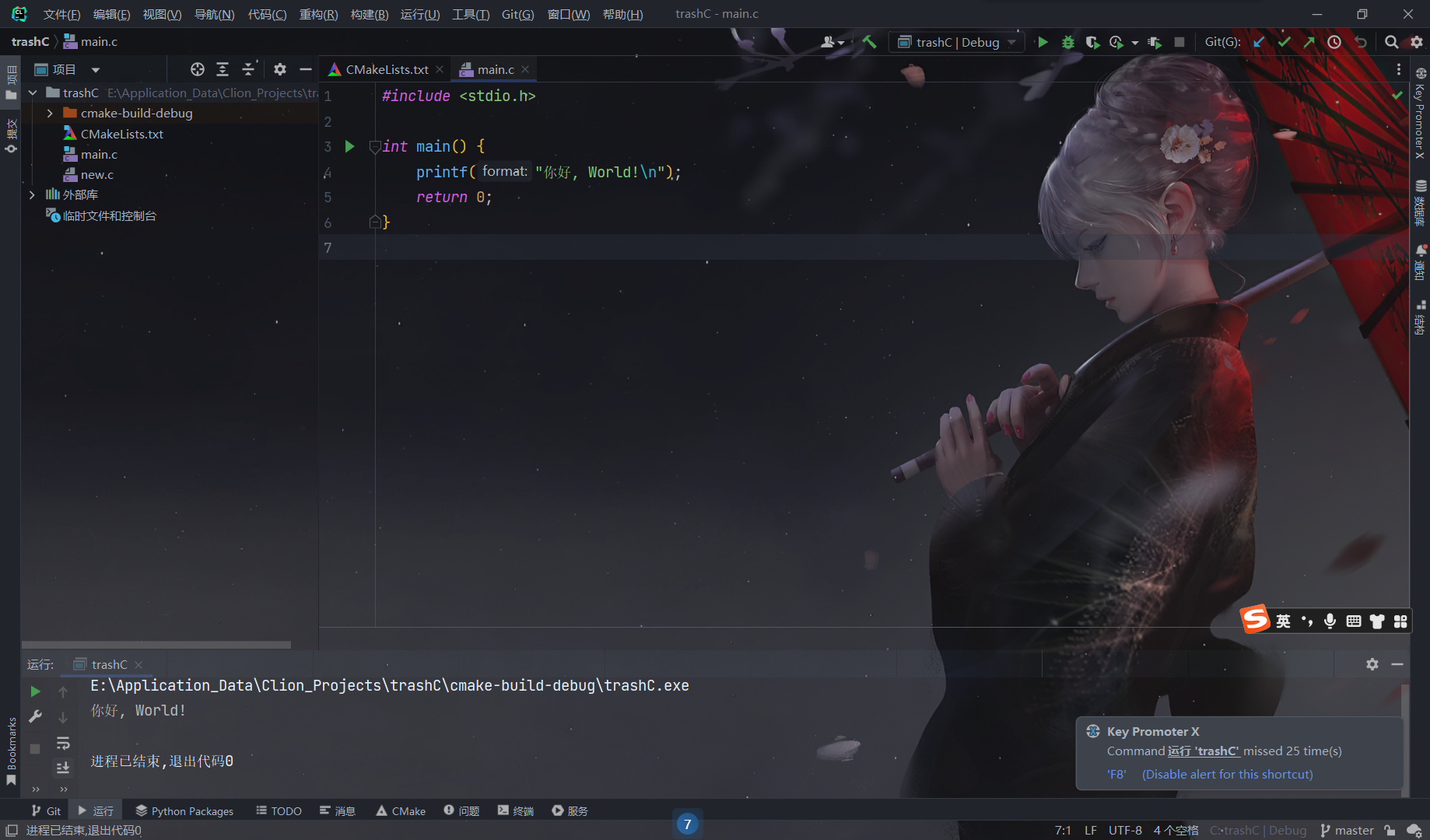
但是可以预见的是,如果将文件编码改为GB2312,则不能正常进行显示了。
至此,针对该问题的内容已经全部结束了。
不过,笔者还想提醒一句:请注意修改IDE编码的时候其给你的提示,是将文件转化为另一编码还是以另一编码重新加载,这两者中的微妙区别相信对于已经读到这里的读者理解起来不算什么难事。
2022.9.27
某不知名学长
博主写得不错,赞一个